Building AI Agents with VoltAgent
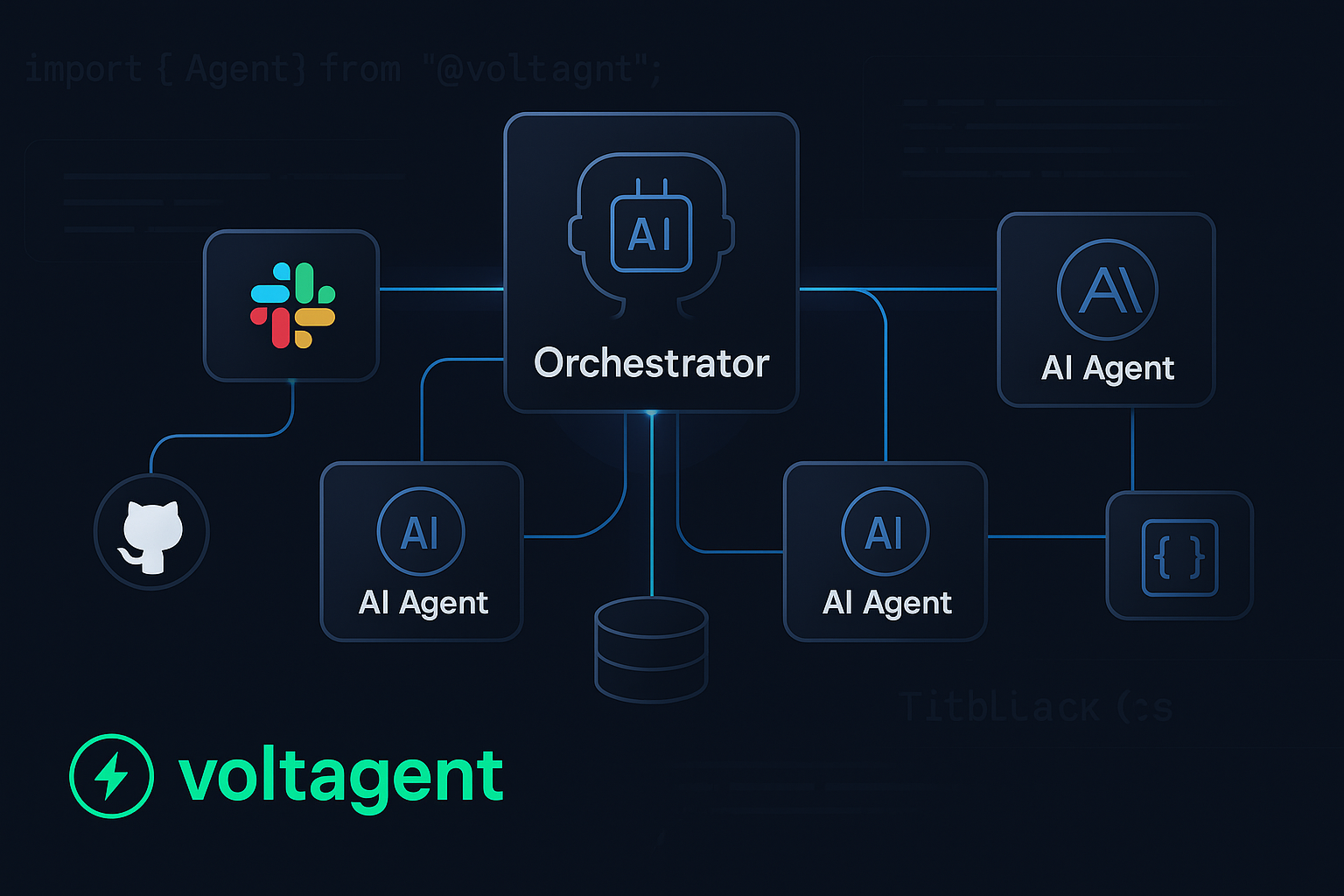
How we built 999 Dev, an AI-powered engineering agent that integrates Slack, GitHub, and Linear using VoltAgent's multi-agent architecture
Introduction
The AI agent space has exploded in 2025, but most frameworks fall into two camps: overly simplistic no-code builders that hit walls quickly, or complex DIY solutions that require building everything from scratch. At 999 Dev, we needed something different—a framework that could scale from simple chatbots to complex multi-agent workflows while giving us full control over the implementation.
After evaluating several options, we chose VoltAgent, an open-source TypeScript AI agent framework that strikes the perfect balance between power and simplicity. In this post, I'll share how we built a production-ready AI engineering platform using VoltAgent's multi-agent architecture, complete with Slack integration, memory management, and sophisticated tool orchestration.
Why VoltAgent?
Before diving into our implementation, let me explain why we chose VoltAgent over alternatives like LangChain, AutoGen, or custom solutions:
1. TypeScript-First Design
VoltAgent was built for TypeScript from the ground up. This isn't just about type safety—it's about developer experience. Having strong types for agent configurations, tool parameters, and message flows prevents entire classes of runtime errors.
const agent = new Agent({
name: "999 Dev Slack Agent",
description: "Specialized agent for Slack communications",
llm: new VercelAIProvider(), // Assuming VercelAIProvider is a valid class
model: openai("gpt-4.1"), // Assuming openai is a valid function
tools: [replyTool, lookupUserTool], // Fully typed
});
2. Provider Agnostic
We can switch between OpenAI, Anthropic, or any AI-SDK provider without rewriting our agents. This flexibility is crucial for production systems where you need to optimize for cost, performance, or capabilities.
3. Multi-Agent Architecture
VoltAgent's supervisor/sub-agent pattern solved our biggest challenge: coordinating specialized agents while maintaining context and memory across interactions.
4. Visual Debugging
The VoltOps observability platform gives us real-time visibility into agent interactions, tool executions, and memory operations—essential for production debugging.
Our Architecture: 999 Dev AI Engineering Platform
999 Dev is an AI-powered engineering agent that functions as a comprehensive team collaboration tool. Here's how we architected it using VoltAgent:
The Multi-Agent Setup
We implemented a two-tier agent architecture:
// Specialized Slack agent
const slackAgent = new Agent({
name: "999 Dev Slack Agent",
description: `Specialized agent for handling all Slack communications
and interactions. Processes messages, manages user interactions,
and executes Slack-specific operations.`,
model: openai("gpt-4.1"),
llm: new VercelAIProvider(),
});
// Orchestrator that manages the slack agent
const orchestratorAgent = new Agent({
name: "999 Dev Orchestrator",
instructions: `Central coordinator for the 999 Dev platform.
Analyzes requests, manages contextual memory, and delegates
tasks to specialized agents.`,
model: openai("gpt-4.1"),
llm: new VercelAIProvider(),
subAgents: [slackAgent], // An array of Agent instances
retriever: slackRetriever, // An instance of a class extending BaseRetriever
});
The code snippets above assume `Agent`, `VercelAIProvider`, `openai`, `replyTool`, `lookupUserTool`, and `slackRetriever` are defined elsewhere in the VoltAgent framework or the user's codebase.
Why This Architecture Works
- Separation of Concerns: The orchestrator handles memory management and task delegation, while the Slack agent focuses purely on Slack operations.
- Scalability: We can easily add GitHub and Linear agents without changing existing code—just add them to the orchestrator's
subAgentsarray. - Context Management: The orchestrator maintains cross-agent context while specialized agents handle domain-specific tasks.
Implementing Smart Memory with RAG
One of our key innovations was implementing contextual memory using VoltAgent's retriever system combined with Supermemory for vector storage:
// Assuming BaseRetriever, SlackRetrieverInput, and supermemory are defined
// For example:
// import { BaseRetriever } from 'voltagent-sdk';
// import { SupermemoryClient } from '@supermemory/client';
// const supermemory = new SupermemoryClient(process.env.SUPERMEMORY_API_KEY);
// interface SlackRetrieverInput {
// eventData: { text: string };
// accountId: string;
// }
// interface MemoryChunk { isRelevant: boolean; score: number; }
// interface MemoryResult { chunks: MemoryChunk[]; score: number; summary?: string; content: string; }
export class SlackRetriever extends BaseRetriever {
// Helper to format memory for RAG - actual implementation would vary
private formatMemoryForRAG(memory: any, relevantChunks: any[], index: number): string {
return `Memory ${index + 1} (Score: ${memory.score.toFixed(2)}):\nSummary: ${memory.summary || 'N/A'}\nContent: ${memory.content}\nRelevant Chunks: ${relevantChunks.length}`;
}
async retrieve(input: string): Promise<string> {
const slackMessage = JSON.parse(input) as SlackRetrieverInput;
const memories = await supermemory.search.execute({
q: slackMessage.eventData.text,
rewriteQuery: true,
rerank: true,
limit: 10,
chunkThreshold: 0.3,
documentThreshold: 0.2,
includeSummary: true,
containerTags: [slackMessage.accountId], // Ensure accountId is a string
});
// Structure the best data for RAG
const extractedData = memories.results
.map((memory: any, index: number) => { // Added 'any' for brevity, define proper types
const relevantChunks = memory.chunks.filter(
(chunk: any) => chunk.isRelevant && chunk.score > 0.5
);
if (relevantChunks.length === 0 && memory.score < 0.3) {
return null;
}
return this.formatMemoryForRAG(memory, relevantChunks, index);
})
.filter(Boolean)
.join("\n\n");
if (!extractedData.trim()) {
return "=== No relevant memories found ===";
}
return `=== Retrieved Memories ===\n${extractedData}`;
}
}
Memory Strategy
Our orchestrator agent is configured to be "extremely liberal" with memory storage:
- Store everything: User preferences, project details, technical decisions, conversation context
- Granular memories: Each meaningful piece of information gets its own memory entry
- Continuous updates: Store memories throughout conversations, not just at the end
- Context-aware retrieval: Include relevant memories when delegating to sub-agents
This approach ensures our agents have rich context for every interaction, creating more natural and helpful conversations.
Building Production-Ready Tools
VoltAgent's tool system made it easy to create a comprehensive suite of Slack integrations. Here's how we structured our tools:
Tool Organization
src/modules/agent/tools/
├── slack/
│ ├── replyToMessage/
│ ├── sendMessageToUser/
│ ├── lookupUserInfo/
│ ├── parseUserMentions/
│ ├── searchMessages/
│ └── addReaction/
└── orchestrator/
└── addMemory/